

Regardless of the proliferation of knowledge and knowledge in enterprise environments, workers and stakeholders typically discover themselves looking for info and struggling to get their questions answered rapidly and effectively. This could result in productiveness losses, frustration, and delays in decision-making.
A generative AI Slack chat assistant will help tackle these challenges by offering a available, clever interface for customers to work together with and procure the data they want. Through the use of the pure language processing and technology capabilities of generative AI, the chat assistant can perceive person queries, retrieve related info from numerous knowledge sources, and supply tailor-made, contextual responses.
By harnessing the ability of generative AI and Amazon Internet Providers (AWS) providers Amazon Bedrock, Amazon Kendra, and Amazon Lex, this answer offers a pattern structure to construct an clever Slack chat assistant that may streamline info entry, improve person experiences, and drive productiveness and effectivity inside organizations.
Why use Amazon Kendra for constructing a RAG software?
Amazon Kendra is a completely managed service that gives out-of-the-box semantic search capabilities for state-of-the-art rating of paperwork and passages. You should use Amazon Kendra to rapidly construct high-accuracy generative AI purposes on enterprise knowledge and supply essentially the most related content material and paperwork to maximise the standard of your Retrieval Augmented Era (RAG) payload, yielding higher giant language mannequin (LLM) responses than utilizing standard or keyword-based search options. Amazon Kendra gives simple-to-use deep studying search fashions which are pre-trained on 14 domains and don’t require machine studying (ML) experience. Amazon Kendra can index content material from a variety of sources, together with databases, content material administration techniques, file shares, and internet pages.
Additional, the FAQ function in Amazon Kendra enhances the broader retrieval capabilities of the service, permitting the RAG system to seamlessly swap between offering prewritten FAQ responses and dynamically producing responses by querying the bigger information base. This makes it well-suited for powering the retrieval part of a RAG system, permitting the mannequin to entry a broad information base when producing responses. By integrating the FAQ capabilities of Amazon Kendra right into a RAG system, the mannequin can use a curated set of high-quality, authoritative solutions for generally requested questions. This could enhance the general response high quality and person expertise, whereas additionally decreasing the burden on the language mannequin to generate these primary responses from scratch.
This answer balances retaining customizations when it comes to mannequin choice, immediate engineering, and including FAQs with not having to cope with phrase embeddings, doc chunking, and different lower-level complexities sometimes required for RAG implementations.
Resolution overview
The chat assistant is designed to help customers by answering their questions and offering info on a wide range of subjects. The aim of the chat assistant is to be an internal-facing Slack instrument that may assist workers and stakeholders discover the data they want.
The structure makes use of Amazon Lex for intent recognition, AWS Lambda for processing queries, Amazon Kendra for looking by way of FAQs and internet content material, and Amazon Bedrock for producing contextual responses powered by LLMs. By combining these providers, the chat assistant can perceive pure language queries, retrieve related info from a number of knowledge sources, and supply humanlike responses tailor-made to the person’s wants. The answer showcases the ability of generative AI in creating clever digital assistants that may streamline workflows and improve person experiences primarily based on mannequin decisions, FAQs, and modifying system prompts and inference parameters.
Structure diagram
The next diagram illustrates a RAG strategy the place the person sends a question by way of the Slack software and receives a generated response primarily based on the information listed in Amazon Kendra. On this submit, we use Amazon Kendra Internet Crawler as the information supply and embrace FAQs saved on Amazon Easy Storage Service (Amazon S3). See Knowledge supply connectors for a listing of supported knowledge supply connectors for Amazon Kendra.

The step-by-step workflow for the structure is the next:
- The person sends a question comparable to
What's the AWS Effectively-Architected Framework?by way of the Slack app. - The question goes to Amazon Lex, which identifies the intent.
- Presently two intents are configured in Amazon Lex (
WelcomeandFallbackIntent). - The welcome intent is configured to reply with a greeting when a person enters a greeting comparable to “hello” or “howdy.” The assistant responds with “Hiya! I will help you with queries primarily based on the paperwork offered. Ask me a query.”
- The fallback intent is fulfilled with a Lambda perform.
- The Lambda perform searches Amazon Kendra FAQs by way of the
search_Kendra_FAQmethodology by taking the person question and Amazon Kendra index ID as inputs. If there’s a match with a excessive confidence rating, the reply from the FAQ is returned to the person. - If there isn’t a match with a excessive sufficient confidence rating, related paperwork from Amazon Kendra with a excessive confidence rating are retrieved by way of the
kendra_retrieve_documentmethodology and despatched to Amazon Bedrock to generate a response because the context. - The response is generated from Amazon Bedrock with the
invokeLLMmethodology. The next is a snippet of theinvokeLLMmethodology throughout the success perform. Learn extra on inference parameters and system prompts to switch parameters which are handed into the Amazon Bedrock invoke mannequin request. - Lastly, the response generated from Amazon Bedrock together with the related referenced URLs are returned to the tip person.
When choosing web sites to index, adhere to the AWS Acceptable Use Coverage and different AWS phrases. Keep in mind which you could solely use Amazon Kendra Internet Crawler to index your individual internet pages or internet pages that you’ve authorization to index. Go to the Amazon Kendra Internet Crawler knowledge supply information to be taught extra about utilizing the net crawler as an information supply. Utilizing Amazon Kendra Internet Crawler to aggressively crawl web sites or internet pages you don’t personal is not thought-about acceptable use.
Supported options
The chat assistant helps the next options:
- Assist for the next Anthropic’s fashions on Amazon Bedrock:
claude-v2claude-3-haiku-20240307-v1:0claude-instant-v1claude-3-sonnet-20240229-v1:0
- Assist for FAQs and the Amazon Kendra Internet Crawler knowledge supply
- Returns FAQ solutions provided that the boldness rating is
VERY_HIGH - Retrieves solely paperwork from Amazon Kendra which have a
HIGHorVERY_HIGHconfidence rating - If paperwork with a excessive confidence rating aren’t discovered, the chat assistant returns “No related paperwork discovered”
Conditions
To carry out the answer, it’s worthwhile to have following conditions:
- Fundamental information of AWS
- An AWS account with entry to Amazon S3 and Amazon Kendra
- An S3 bucket to retailer your paperwork. For extra info, see Step 1: Create your first S3 bucket and the Amazon S3 Consumer Information.
- A Slack workspace to combine the chat assistant
- Permission to put in Slack apps in your Slack workspace
- Seed URLs for the Amazon Kendra Internet Crawler knowledge supply
- You’ll want authorization to crawl and index any web sites offered
- AWS CloudFormation for deploying the answer sources
Construct a generative AI Slack chat assistant
To construct a Slack software, use the next steps:
- Request mannequin entry on Amazon Bedrock for all Anthropic fashions
- Create an S3 bucket within the
us-east-1(N. Virginia) AWS Area. - Add the AIBot-LexJson.zip and SampleFAQ.csv recordsdata to the S3 bucket
- Launch the CloudFormation stack within the
us-east-1(N. Virginia) AWS Area.
- Enter a Stack identify of your alternative
- For S3BucketName, enter the identify of the S3 bucket created in Step 2
- For S3KendraFAQKey, enter the identify of the
SampleFAQsuploaded to the S3 bucket in Step 3 - For S3LexBotKey, enter the identify of the Amazon Lex .zip file uploaded to the S3 bucket in Step 3
- For SeedUrls, enter as much as 10 URLs for the net crawler as a comma delimited listing. Within the instance on this submit, we give the publicly accessible Amazon Bedrock service web page because the seed URL
- Go away the remaining as defaults. Select Subsequent. Select Subsequent once more on the Configure stack choices
- Acknowledge by choosing the field and select Submit, as proven within the following screenshot

- Look ahead to the stack creation to finish
- Confirm all sources are created
- Check on the AWS Administration Console for Amazon Lex
- On the Amazon Lex console, select your chat assistant
${YourStackName}-AIBot - Select Intents
- Select Model 1 and select Check, as proven within the following screenshot
- Choose the AIBotProdAlias and select Affirm, as proven within the following screenshot. If you wish to make modifications to the chat assistant, you need to use the draft model, publish a brand new model, and assign the brand new model to the
AIBotProdAlias. Study extra about Versioning and Aliases.
- Check the chat assistant with questions comparable to, “Which AWS service has 11 nines of sturdiness?” and “What’s the AWS Effectively-Architected Framework?” and confirm the responses. The next desk exhibits that there are three FAQs within the pattern .csv file.
_question _answer _source_uri Which AWS service has 11 nines of sturdiness? Amazon S3 https://aws.amazon.com/s3/ What’s the AWS Effectively-Architected Framework? The AWS Effectively-Architected Framework allows prospects and companions to evaluate their architectures utilizing a constant strategy and offers steerage to enhance designs over time. https://aws.amazon.com/structure/well-architected/ In what Areas is Amazon Kendra accessible? Amazon Kendra is at present accessible within the following AWS Areas: Northern Virginia, Oregon, and Eire https://aws.amazon.com/about-aws/global-infrastructure/regional-product-services/ - The next screenshot exhibits the query
“Which AWS service has 11 nines of sturdiness?”and its response. You possibly can observe that the response is identical as within the FAQ file and features a hyperlink.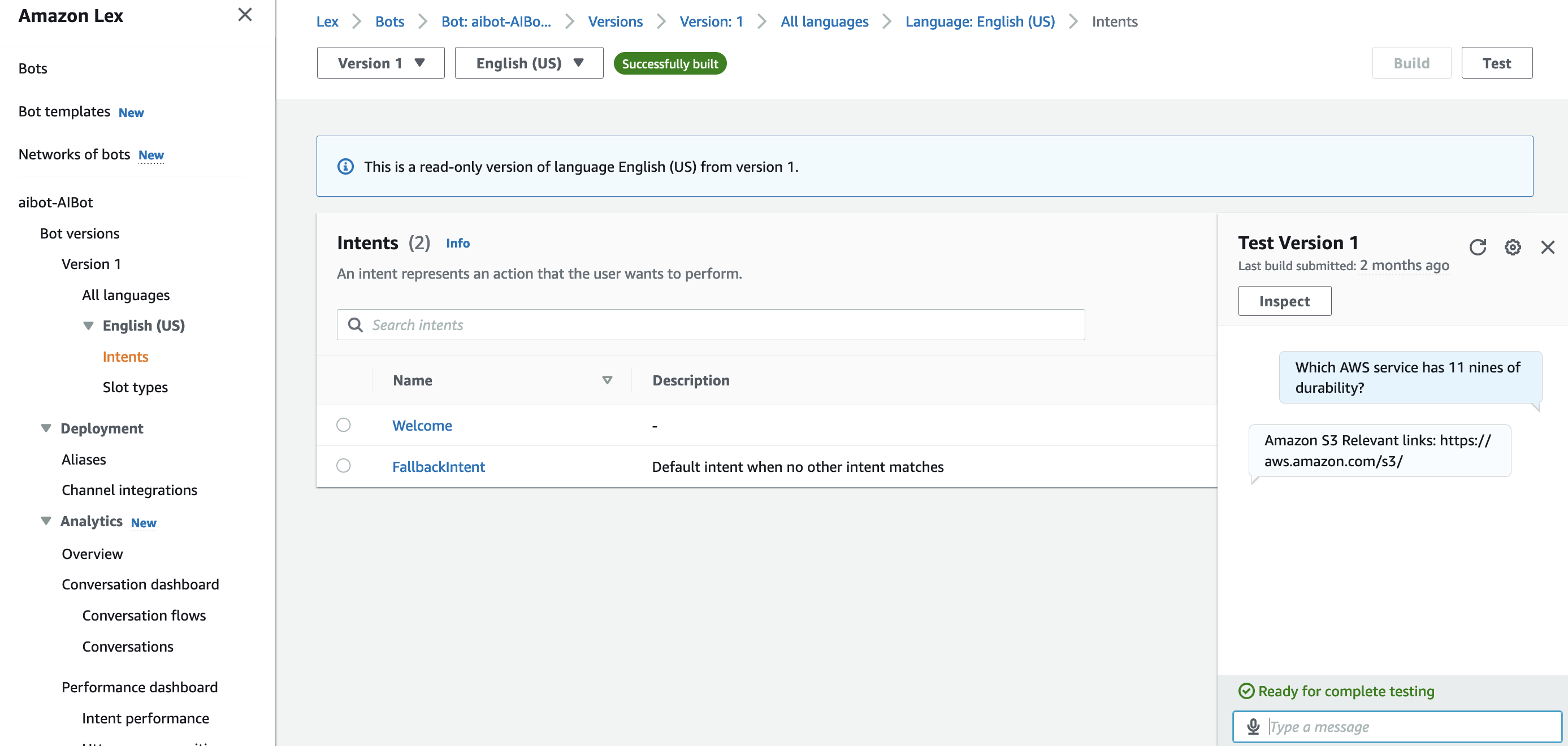
- Primarily based on the pages you’ve crawled, ask a query within the chat. For this instance, the publicly accessible Amazon Bedrock web page was crawled and listed. The next screenshot exhibits the query,
“What are brokers in Amazon Bedrock?”and and a generated response that features related hyperlinks.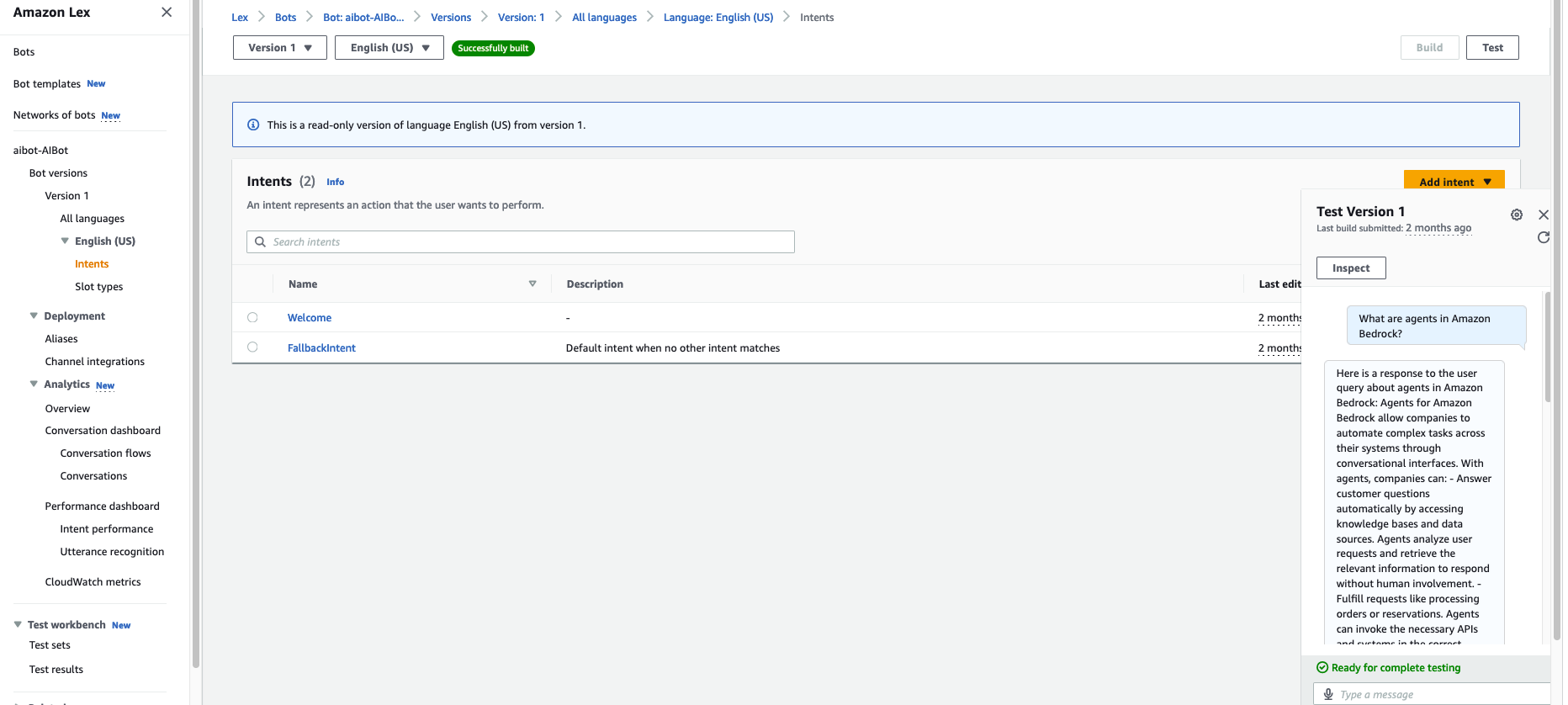
- On the Amazon Lex console, select your chat assistant
- For integration of the Amazon Lex chat assistant with Slack, see Integrating an Amazon Lex V2 bot with Slack. Select the AIBotProdAlias beneath Alias within the Channel Integrations
Run pattern queries to check the answer
- In Slack, go to the Apps part. Within the dropdown menu, select Handle and choose Browse apps.
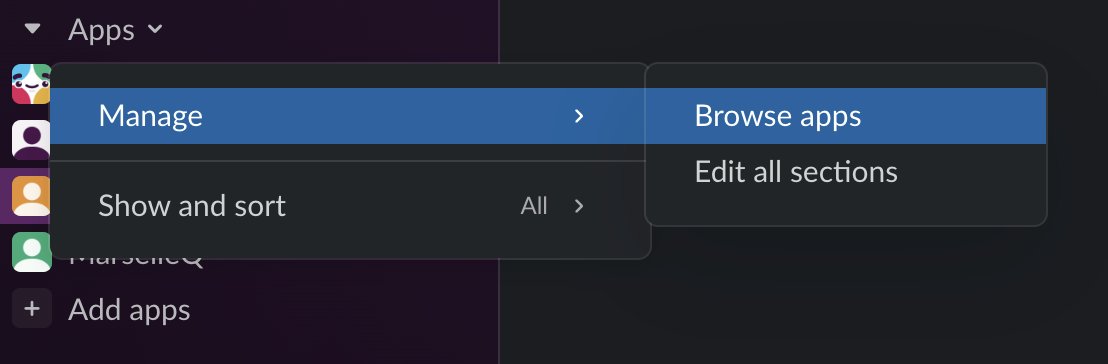
- Seek for
${AIBot}in App Listing and select the chat assistant. It will add the chat assistant to the Apps part in Slack. Now you can begin asking questions within the chat. The next screenshot exhibits the query“Which AWS service has 11 nines of sturdiness?”and its response. You possibly can observe that the response is identical as within the FAQ file and features a hyperlink.
- The next screenshot exhibits the query,
“What's the AWS Effectively-Architected Framework?”and its response.
- Primarily based on the pages you’ve crawled, ask a query within the chat. For this instance, the publicly accessible Amazon Bedrock web page was crawled and listed. The next screenshot exhibits the query,
“What are brokers in Amazon Bedrock?”and and a generated response that features related hyperlinks.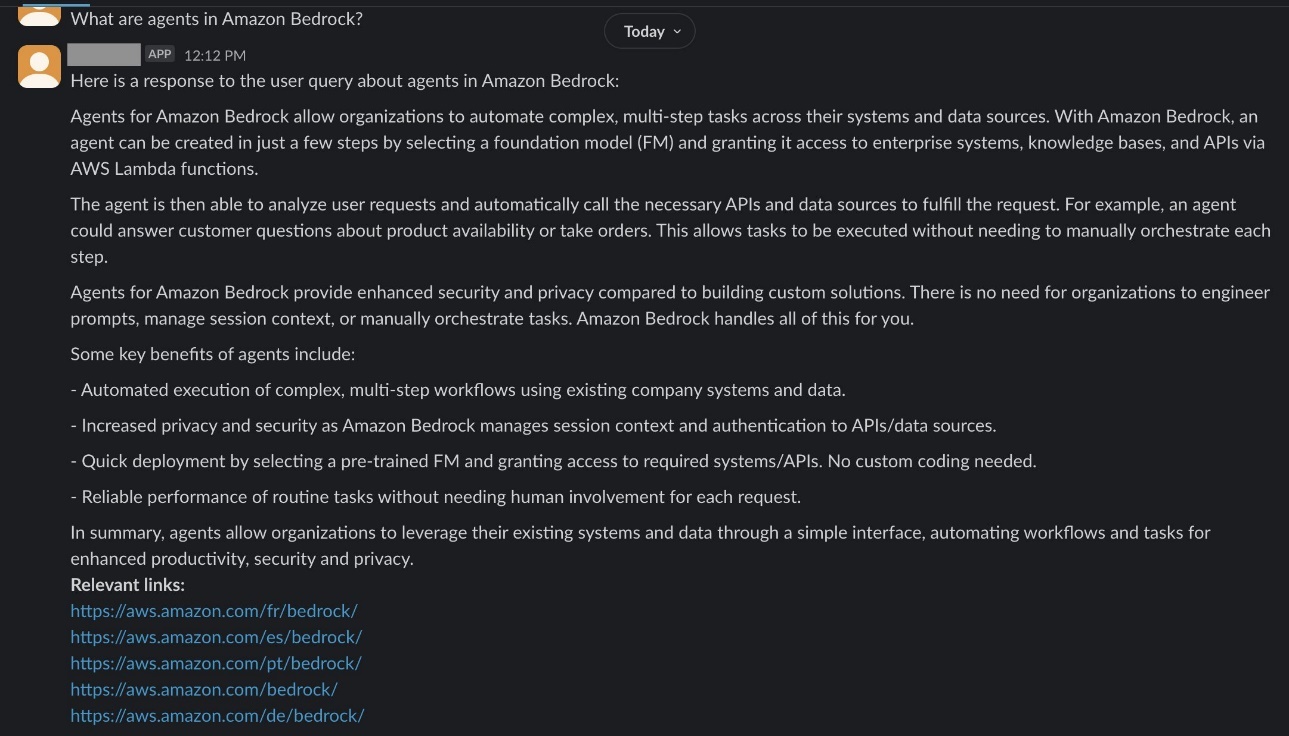
- The next screenshot exhibits the query,
“What's amazon polly?”As a result of there isn’t a Amazon Polly documentation listed, the chat assistant responds with “No related paperwork discovered,” as anticipated.
These examples present how the chat assistant retrieves paperwork from Amazon Kendra and offers solutions primarily based on the paperwork retrieved. If no related paperwork are discovered, the chat assistant responds with “No related paperwork discovered.”
Clear up
To wash up the sources created by this answer:
- Delete the CloudFormation stack by navigating to the CloudFormation console
- Choose the stack you created for this answer and select Delete
- Affirm the deletion by coming into the stack identify within the offered area. It will take away all of the sources created by the CloudFormation template, together with the Amazon Kendra index, Amazon Lex chat assistant, Lambda perform, and different associated sources.
Conclusion
This submit describes the event of a generative AI Slack software powered by Amazon Bedrock and Amazon Kendra. That is designed to be an internal-facing Slack chat assistant that helps reply questions associated to the listed content material. The answer structure contains Amazon Lex for intent identification, a Lambda perform for fulfilling the fallback intent, Amazon Kendra for FAQ searches and indexing crawled internet pages, and Amazon Bedrock for producing responses. The submit walks by way of the deployment of the answer utilizing a CloudFormation template, offers directions for operating pattern queries, and discusses the steps for cleansing up the sources. Total, this submit demonstrates use numerous AWS providers to construct a strong generative AI–powered chat assistant software.
This answer demonstrates the ability of generative AI in constructing clever chat assistants and search assistants. Discover the generative AI Slack chat assistant: Invite your groups to a Slack workspace and begin getting solutions to your listed content material and FAQs. Experiment with totally different use instances and see how one can harness the capabilities of providers like Amazon Bedrock and Amazon Kendra to reinforce what you are promoting operations. For extra details about utilizing Amazon Bedrock with Slack, discuss with Deploy a Slack gateway for Amazon Bedrock.
In regards to the authors
 Kruthi Jayasimha Rao is a Companion Options Architect with a give attention to AI and ML. She offers technical steerage to AWS Companions in following greatest practices to construct safe, resilient, and extremely accessible options within the AWS Cloud.
Kruthi Jayasimha Rao is a Companion Options Architect with a give attention to AI and ML. She offers technical steerage to AWS Companions in following greatest practices to construct safe, resilient, and extremely accessible options within the AWS Cloud. Mohamed Mohamud is a Companion Options Architect with a give attention to Knowledge Analytics. He makes a speciality of streaming analytics, serving to companions construct real-time knowledge pipelines and analytics options on AWS. With experience in providers like Amazon Kinesis, Amazon MSK, and Amazon EMR, Mohamed allows data-driven decision-making by way of streaming analytics.
Mohamed Mohamud is a Companion Options Architect with a give attention to Knowledge Analytics. He makes a speciality of streaming analytics, serving to companions construct real-time knowledge pipelines and analytics options on AWS. With experience in providers like Amazon Kinesis, Amazon MSK, and Amazon EMR, Mohamed allows data-driven decision-making by way of streaming analytics. - The Lambda perform searches Amazon Kendra FAQs by way of the

{kind=link}