

{kind=link}
Chatbots have gotten useful instruments for companies, serving to to enhance effectivity and assist workers. By sifting by means of troves of firm information and documentation, LLMs can assist employees by offering knowledgeable responses to a variety of inquiries. For knowledgeable workers, this may also help reduce time spent in redundant, much less productive duties. For newer workers, this can be utilized to not solely velocity the time to an accurate reply however information these employees by means of on-boarding, assess their data development and even counsel areas for additional studying and growth as they arrive extra absolutely up to the mark.
For the foreseeable future, these capabilities seem poised to increase employees greater than to switch them. And with looming challenges in employee availability in lots of developed economies, many organizations are rewiring their inner processes to benefit from the assist they’ll present.
Scaling LLM-Based mostly Chatbots Can Be Costly
As companies put together to extensively deploy chatbots into manufacturing, many are encountering a major problem: price. Excessive-performing fashions are sometimes costly to question, and plenty of fashionable chatbot purposes, often known as agentic methods, might decompose particular person consumer requests into a number of, more-targeted LLM queries with a purpose to synthesize a response. This could make scaling throughout the enterprise prohibitively costly for a lot of purposes.
However take into account the breadth of questions being generated by a gaggle of workers. How dissimilar is every query? When particular person workers ask separate however comparable questions, might the response to a earlier inquiry be re-used to deal with some or all the wants of a latter one? If we might re-use a number of the responses, what number of calls to the LLM might be prevented and what may the price implications of this be?
Reusing Responses May Keep away from Pointless Value
Think about a chatbot designed to reply questions on an organization’s product options and capabilities. Through the use of this device, workers may be capable of ask questions with a purpose to assist numerous engagements with their prospects.
In a regular strategy, the chatbot would ship every question to an underlying LLM, producing almost equivalent responses for every query. But when we programmed the chatbot software to first search a set of beforehand cached questions and responses for extremely comparable inquiries to the one being requested by the consumer and to make use of an current response every time one was discovered, we might keep away from redundant calls to the LLM. This system, often known as semantic caching, is turning into extensively adopted by enterprises due to the price financial savings of this strategy.
Constructing a Chatbot with Semantic Caching on Databricks
At Databricks, we function a public-facing chatbot for answering questions on our merchandise. This chatbot is uncovered in our official documentation and sometimes encounters comparable consumer inquiries. On this weblog, we consider Databricks’ chatbot in a sequence of notebooks to know how semantic caching can improve effectivity by decreasing redundant computations. For demonstration functions, we used a synthetically generated dataset, simulating the kinds of repetitive questions the chatbot may obtain.
Databricks Mosaic AI gives all the mandatory elements to construct a cost-optimized chatbot answer with semantic caching, together with Vector Seek for making a semantic cache, MLflow and Unity Catalog for managing fashions and chains, and Mannequin Serving for deploying and monitoring, in addition to monitoring utilization and payloads. To implement semantic caching, we add a layer initially of the usual Retrieval-Augmented Era (RAG) chain. This layer checks if an analogous query already exists within the cache; if it does, then the cached response is retrieved and served. If not, the system proceeds with executing the RAG chain. This straightforward but highly effective routing logic may be simply applied utilizing open supply instruments like Langchain or MLflow’s pyfunc.
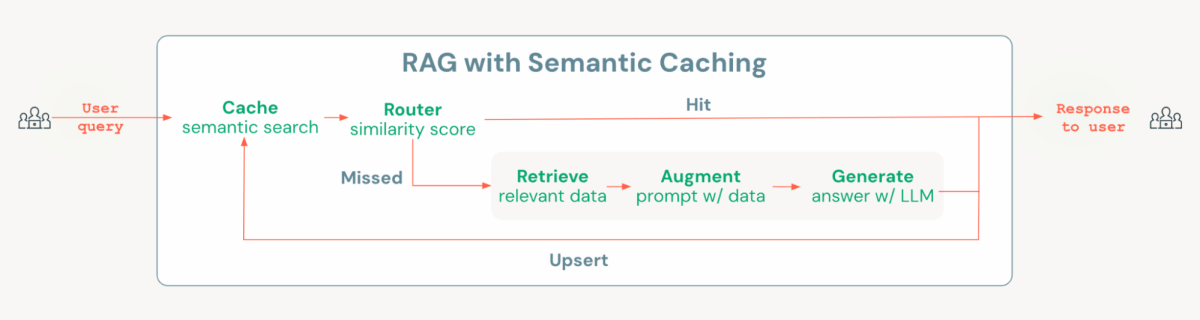
Within the notebooks, we show the right way to implement this answer on Databricks, highlighting how semantic caching can scale back each latency and prices in comparison with a regular RAG chain when examined with the identical set of questions.
Along with the effectivity enchancment, we additionally present how semantic caching impacts the response high quality utilizing an LLM-as-a-judge strategy in MLflow. Whereas semantic caching improves effectivity, there’s a slight drop in high quality: analysis outcomes present that the usual RAG chain carried out marginally higher in metrics reminiscent of reply relevance. These small declines in high quality are anticipated when retrieving responses from the cache. The important thing takeaway is to find out whether or not these high quality variations are acceptable given the numerous price and latency reductions supplied by the caching answer. In the end, the choice needs to be primarily based on how these trade-offs have an effect on the general enterprise worth of your use case.
Why Databricks?
Databricks gives an optimum platform for constructing cost-optimized chatbots with caching capabilities. With Databricks Mosaic AI, customers have native entry to all essential elements, particularly a vector database, agent growth and analysis frameworks, serving, and monitoring on a unified, extremely ruled platform. This ensures that key property, together with information, vector indexes, fashions, brokers, and endpoints, are centrally managed below sturdy governance.
Databricks Mosaic AI additionally presents an open structure, permitting customers to experiment with numerous fashions for embeddings and era. Leveraging the Databricks Mosaic AI Agent Framework and Analysis instruments, customers can quickly iterate on purposes till they meet production-level requirements. As soon as deployed, KPIs like hit ratios and latency may be monitored utilizing MLflow traces, that are robotically logged in Inference Tables for straightforward monitoring.
Should you’re trying to implement semantic caching on your AI system on Databricks, take a look at this challenge that’s designed that will help you get began shortly and effectively.