

{kind=link}
Amazon Rufus is a procuring assistant expertise powered by generative AI. It generates solutions utilizing related info from throughout Amazon and the net to assist Amazon prospects make higher, extra knowledgeable procuring selections. With Rufus, prospects can store alongside a generative AI-powered knowledgeable that is aware of Amazon’s choice inside and outside, and may deliver all of it along with info from throughout the net to assist consumers make extra knowledgeable buy selections.
To fulfill the wants of Amazon prospects at scale, Rufus required a low-cost, performant, and extremely out there infrastructure for inference. The answer wanted the potential to serve multi-billion parameter giant language fashions (LLMs) with low latency internationally to service its expansive buyer base. Low latency makes certain customers have a constructive expertise chatting with Rufus and may begin getting responses in lower than a second. To attain this, the Rufus staff is utilizing a number of AWS providers and AWS AI chips, AWS Trainium and AWS Inferentia.
Inferentia and Trainium are purpose-built chips developed by AWS that speed up deep studying workloads with excessive efficiency and decrease general prices. With these chips, Rufus lowered its prices by 4.5 instances decrease than different evaluated options whereas sustaining low latency for its prospects. On this put up, we dive into the Rufus inference deployment utilizing AWS chips and the way this enabled one of the vital demanding occasions of the yr—Amazon Prime Day.
Resolution overview
At its core, Rufus is powered by an LLM educated on Amazon’s product catalog and knowledge from throughout the net. LLM deployment will be difficult, requiring you to steadiness components resembling mannequin measurement, mannequin accuracy, and inference efficiency. Bigger fashions usually have higher information and reasoning capabilities however come at the next value resulting from extra demanding compute necessities and growing latency. Rufus would must be deployed and scale to satisfy the large demand of peak occasions like Amazon Prime Day. Concerns for this scale embody how nicely it must carry out, its environmental influence, and the price of internet hosting the answer. To fulfill these challenges, Rufus used a mixture of AWS options: Inferentia2 and Trainium, Amazon Elastic Container Service (Amazon ECS), and Utility Load Balancer (ALB). As well as, the Rufus staff partnered with NVIDIA to energy the answer utilizing NVIDIA’s Triton Inference Server, offering capabilities to host the mannequin utilizing AWS chips.
Rufus inference is a Retrieval Augmented Technology (RAG) system with responses enhanced by retrieving extra info resembling product info from Amazon search outcomes. These outcomes are based mostly on the client question, ensuring the LLM generates dependable, high-quality, and exact responses.
To ensure Rufus was greatest positioned for Prime Day, the Rufus staff constructed a heterogeneous inference system utilizing a number of AWS Areas powered by Inferentia2 and Trainium. Constructing a system throughout a number of Areas allowed Rufus to learn in two key areas. First, it supplied extra capability that could possibly be used throughout instances of excessive demand, and second, it improved the general resiliency of the system.
The Rufus staff was additionally ready to make use of each Inf2 and Trn1 occasion varieties. As a result of Inf2 and Trn1 occasion varieties use the identical AWS Neuron SDK, the Rufus staff was ready to make use of each situations to serve the identical Rufus mannequin. The one configuration setting to regulate was the tensor parallelism diploma (24 for Inf2, 32 for Trn1). Utilizing Trn1 situations additionally led to a further 20% latency discount and throughput enchancment in comparison with Inf2.
The next diagram illustrates the answer structure.

To assist real-time site visitors routing throughout a number of Areas, Rufus constructed a novel site visitors orchestrator. Amazon CloudWatch supported the underlying monitoring, serving to the staff alter the site visitors ratio throughout the completely different Areas in lower than quarter-hour based mostly on the site visitors sample adjustments. Through the use of the sort of orchestration, the Rufus staff had the flexibility to direct requests to different Areas when wanted, with a small trade-off of latency to the primary token. On account of Rufus’s streaming structure and the performant AWS community between Areas, the perceived latency was minimal for end-users.
These selections allowed Rufus to scale up over 80,000 Trainium and Inferentia chips throughout three Areas serving a median of three million tokens a minute whereas sustaining P99 lower than 1 second latency to the primary response for Prime Day prospects. As well as, by utilizing these purpose-built chips, Rufus achieved 54% higher efficiency per watt than different evaluated options, which helped the Rufus staff meet vitality effectivity objectives.
Optimizing inference efficiency and host utilization
Inside every Area, the Rufus inference system used Amazon ECS, which managed the underlying Inferentia and Trainium powered situations. By managing the underlying infrastructure, the Rufus staff solely wanted to deliver their container and configuration by defining an ECS process. Inside every container, an NVIDIA Triton Inference Server with a Python backend is used operating vLLM with the Neuron SDK. vLLM is a memory-efficient inference and serving engine that’s optimized for prime throughput. The Neuron SDK makes it easy for groups to undertake AWS chips and helps many alternative libraries and frameworks resembling PyTorch Lightning.
The Neuron SDK gives an easy LLM inference answer on Trainium and Inferentia {hardware} with optimized efficiency supporting a variety of transformer-based LLM architectures. To scale back latency, Rufus has collaborated with the AWS Annapurna staff to develop varied optimizations resembling INT8 (weight solely) quantization, steady batching with vLLM, useful resource, compute, and reminiscence bandwidth within the Neuron compiler and runtime. These optimizations are at present deployed in Rufus manufacturing and can be found to make use of within the Neuron SDK 2.18 and onward.
To scale back general ready time for patrons to begin seeing a response from Rufus, the staff additionally developed an inference streaming structure. With the excessive compute and reminiscence load wanted for LLM inference, the whole time it takes to complete producing the complete response for a buyer question can take a number of seconds. With a streaming structure, Rufus is ready to return the tokens proper after they’re generated. This optimization permits the client to begin consuming the response in lower than 1 second. As well as, a number of providers work collectively utilizing gRPC connections to intelligently combination and improve the streaming response in actual time for patrons.
As proven within the following determine, pictures and hyperlinks are embedded within the response, which permit prospects to interact and proceed exploring with Rufus.

Scaling up
Though we’ve got to take care of low latency for the most effective buyer expertise, it’s additionally essential to scale the service throughput by reaching excessive {hardware} useful resource utilization. Excessive {hardware} utilization makes certain accelerators don’t sit idle and needlessly enhance prices. To optimize the inference system throughput, the staff improved each single-host throughput in addition to load balancing effectivity.
Load balancing for LLM inference is difficult resulting from following challenges. First, a single host can solely deal with a restricted variety of concurrent requests. Second, the end-to-end latency to finish one request can differ, spanning many seconds relying on the LLM response size.
To handle the challenges, the staff optimized throughput by contemplating each single-host throughput and throughput throughout many hosts utilizing load balancing.
The staff used the least excellent requests (LOR) routing algorithm from ALB, growing throughput by 5 instances quicker compared to an earlier baseline measurement. This permits every host to have sufficient time to course of in-flight requests and stream again responses utilizing a gRPC connection, with out getting overwhelmed by a number of requests obtained on the similar time. Rufus additionally collaborated with AWS and vLLM groups to enhance single-host concurrency utilizing vLLM integration with the Neuron SDK and NVIDIA Triton Inference Server.
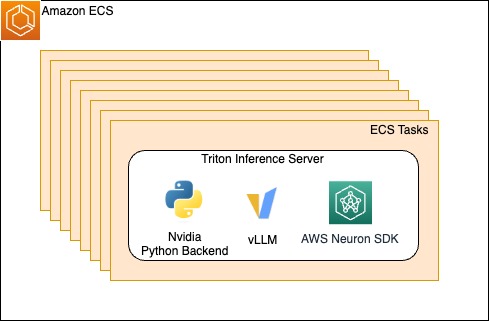
Determine 1. ECS duties scale horizontally internet hosting the Triton Inference Server and dependencies
With this integration, Rufus was capable of profit from a vital optimization: steady batching. Steady batching permits a single host to tremendously enhance throughput. As well as, steady batching gives distinctive capabilities compared to different batch methods, resembling static batching. For instance, when utilizing static batching, the time to first token (TTFT) will increase linearly with the variety of requests in a single batch. Steady batching prioritizes the prefill stage for LLM inference, preserving TTFT beneath management even with extra requests operating on the similar time. This helped Rufus present a pleasing expertise with low latency when producing the primary response, and enhance the single-host throughput to maintain serving prices beneath management.
Conclusion
On this put up, we mentioned how Rufus is ready to reliably deploy and serve its multi-billion-parameter LLM utilizing the Neuron SDK with Inferentia2 and Trainium chips and AWS providers. Rufus continues to evolve with developments in generative AI and buyer suggestions and we encourage you to make use of Inferentia and Trainium.
Study extra about how we’re innovating with generative AI throughout Amazon.
Concerning the writer
 James Park is a Options Architect at Amazon Internet Providers. He works with Amazon.com to design, construct, and deploy know-how options on AWS, and has a specific curiosity in AI and machine studying. In his spare time, he enjoys searching for out new cultures, new experiences, and staying updated with the most recent know-how traits.
James Park is a Options Architect at Amazon Internet Providers. He works with Amazon.com to design, construct, and deploy know-how options on AWS, and has a specific curiosity in AI and machine studying. In his spare time, he enjoys searching for out new cultures, new experiences, and staying updated with the most recent know-how traits.
 RJ is an Engineer inside Amazon. He builds and optimizes techniques for distributed techniques for coaching and works on optimizing adopting techniques to scale back latency for ML Inference. Outdoors work, he’s exploring utilizing Generative AI for constructing meals recipes.
RJ is an Engineer inside Amazon. He builds and optimizes techniques for distributed techniques for coaching and works on optimizing adopting techniques to scale back latency for ML Inference. Outdoors work, he’s exploring utilizing Generative AI for constructing meals recipes.
 Yang Zhou is a software program engineer engaged on constructing and optimizing machine studying techniques. His latest focus is enhancing the efficiency and price effectivity of generative AI inference. Past work, he enjoys touring and has just lately found a ardour for operating lengthy distances.
Yang Zhou is a software program engineer engaged on constructing and optimizing machine studying techniques. His latest focus is enhancing the efficiency and price effectivity of generative AI inference. Past work, he enjoys touring and has just lately found a ardour for operating lengthy distances.
 Adam (Hongshen) Zhao is a Software program Improvement Supervisor at Amazon Shops Foundational AI. In his present function, Adam is main Rufus Inference staff to construct GenAI inference optimization options and inference system at scale for quick inference at low value. Outdoors work, he enjoys touring along with his spouse and artwork creations.
Adam (Hongshen) Zhao is a Software program Improvement Supervisor at Amazon Shops Foundational AI. In his present function, Adam is main Rufus Inference staff to construct GenAI inference optimization options and inference system at scale for quick inference at low value. Outdoors work, he enjoys touring along with his spouse and artwork creations.
 Faqin Zhong is a software program engineer at Amazon Shops Foundational AI, engaged on Giant Language Mannequin (LLM) inference infrastructure and optimizations. Captivated with Generative AI know-how, Faqin collaborates with main groups to drive improvements, making LLMs extra accessible and impactful, in the end enhancing buyer experiences throughout numerous purposes. Outdoors of labor she enjoys cardio train and baking together with her son.
Faqin Zhong is a software program engineer at Amazon Shops Foundational AI, engaged on Giant Language Mannequin (LLM) inference infrastructure and optimizations. Captivated with Generative AI know-how, Faqin collaborates with main groups to drive improvements, making LLMs extra accessible and impactful, in the end enhancing buyer experiences throughout numerous purposes. Outdoors of labor she enjoys cardio train and baking together with her son.
 Nicolas Trown is an engineer in Amazon Shops Foundational AI. His latest focus is lending his techniques experience throughout Rufus to help Rufus Inference staff and environment friendly utilization throughout the Rufus expertise. Outdoors of labor he enjoys spending time along with his spouse and day journeys to close by coast, Napa, and Sonoma areas.
Nicolas Trown is an engineer in Amazon Shops Foundational AI. His latest focus is lending his techniques experience throughout Rufus to help Rufus Inference staff and environment friendly utilization throughout the Rufus expertise. Outdoors of labor he enjoys spending time along with his spouse and day journeys to close by coast, Napa, and Sonoma areas.
 Bing Yin is a director of science at Amazon Shops Foundational AI. He leads the trouble to construct LLMs which can be specialised for procuring use circumstances and optimized for inference at Amazon scale. Outdoors of labor, he enjoys operating marathon races.
Bing Yin is a director of science at Amazon Shops Foundational AI. He leads the trouble to construct LLMs which can be specialised for procuring use circumstances and optimized for inference at Amazon scale. Outdoors of labor, he enjoys operating marathon races.