

{kind=link}
Based in 2017, Logically is a frontrunner in utilizing AI to enhance shoppers’ intelligence functionality. By processing and analyzing huge quantities of information from web sites, social platforms, and different digital sources, Logically identifies potential dangers, rising threats, and important narratives, organizing them into actionable insights that cybersecurity groups, product managers, and engagement leaders can act on swiftly and strategically.
GPU acceleration is a key part in Logically’s platform, enabling the detection of narratives to satisfy the necessities of extremely regulated entities. Through the use of GPUs, Logically has been capable of considerably cut back coaching and inference instances, permitting for information processing on the scale required to fight the unfold of false narratives on social media and the web extra broadly. The present shortage of GPU assets additionally implies that optimizing their utilization is vital for attaining optimum latency and the general success of AI initiatives.
Logically noticed their inference instances growing steadily as their information volumes grew, and due to this fact had a necessity to raised perceive and optimize their cluster utilization. Greater GPU clusters ran fashions sooner however had been underutilized. This commentary led to the thought of profiting from the distribution energy of Spark to carry out GPU mannequin inference in probably the most optimum manner and to find out whether or not an alternate configuration was required to unlock a cluster’s full potential.
By tuning concurrent duties per executor and pushing extra duties per GPU, Logically was capable of cut back the runtime of their flagship advanced fashions by as much as 40%. This weblog explores how.
The important thing levers used had been:
1. Fractional GPU Allocation: Controlling the GPU allocation per activity when Spark schedules GPU assets permits for splitting it evenly throughout the duties on every executor. This enables overlapping I/O and computation for optimum GPU utilization.
The default spark configuration is one activity per GPU, as introduced under. Because of this except a number of information is pushed into every activity, the GPU will doubtless be underutilized.

By setting spark.activity.useful resource.gpu.quantity to values under 1, corresponding to 0.5 or 0.25, Logically achieved a greater distribution of every GPU throughout duties. The most important enhancements had been seen by experimenting with this setting. By lowering the worth of this configuration, extra duties can run in parallel on every GPU, permitting the inference job to complete sooner.

Experimenting with this configuration is an efficient preliminary step and sometimes has probably the most impression with the least tweaking. Within the following configurations, we are going to go a bit deeper into how Spark works and the configurations we tweaked.
2. Concurrent Activity Execution: Making certain that the cluster runs a couple of concurrent activity per executor permits higher parallelization.
In standalone mode, if spark.executor.cores isn’t explicitly set, every executor will use all obtainable cores on the employee node, stopping a fair distribution of GPU assets.
The spark.executor.cores setting could be set to correspond to the spark.activity.useful resource.gpu.quantity setting. As an illustration, spark.executor.cores=2 permits two duties to run on every executor. Given a GPU useful resource splitting of spark.activity.useful resource.gpu.quantity=0.5, these two concurrent duties would run on the identical GPU.
Logically achieved optimum outcomes by operating one executor per GPU and evenly distributing the cores among the many executors. As an illustration, a cluster with 24 cores and 4 GPUs would run with six cores (--conf spark.executor.cores=6) per executor. This controls the variety of duties that Spark places on an executor without delay.

3. Coalesce: Merging present partitions right into a smaller quantity reduces the overhead of managing numerous partitions and permits for extra information to suit into every partition. The relevance of coalesce() to GPUs revolves round information distribution and optimization for environment friendly GPU utilization. GPUs excel at processing giant datasets attributable to their extremely parallel structure, which may execute many operations concurrently. For environment friendly GPU utilization, we have to perceive the next:
- Bigger partitions of information are sometimes higher as a result of GPUs can deal with huge parallel workloads. Bigger partitions additionally result in higher GPU reminiscence utilization, so long as they match into the obtainable GPU reminiscence. If this restrict is exceeded, it’s possible you’ll run into OOMs.
- Underneath-utilized GPUs (attributable to small partitions or small workloads, for easy reads, Spark goals for a partition measurement of 128MB) might result in inefficiencies, with many GPU cores remaining idle.
In these instances, coalesce() can assist by lowering the variety of partitions, guaranteeing that every partition incorporates extra information, which is usually preferable for GPU processing. Bigger information chunks per partition imply that the GPU could be higher utilized, leveraging its parallel cores to course of extra information without delay.
Coalesce combines present partitions to create a smaller variety of partitions, which may enhance efficiency and useful resource utilization in sure situations. When attainable, partitions are merged domestically inside an executor, avoiding a full shuffle of information throughout the cluster.
It’s value noting that coalesce doesn’t assure balanced partitions, which can result in skewed information distribution. In case you realize that your information incorporates skew, then repartition() is most popular, because it performs a full shuffle that redistributes the information evenly throughout partitions. If repartition() works higher to your use case, be sure you flip Adaprite Question Execution (AQE) off with the setting spark.conf.set("spark.databricks.optimizer.adaptive.enabled","false). AQE can dynamically coalesce partitions which can intervene with the optimum partition we try to attain with this train.
By controlling the variety of partitions, the Logically group was capable of push extra information into every partition. Setting the variety of partitions to a a number of of the variety of GPUs obtainable resulted in higher GPU utilization.
Logically experimented with coalesce(8), coalesce(16), coalesce(32) and coalesce(64) and achieved optimum outcomes with coalesce(64).
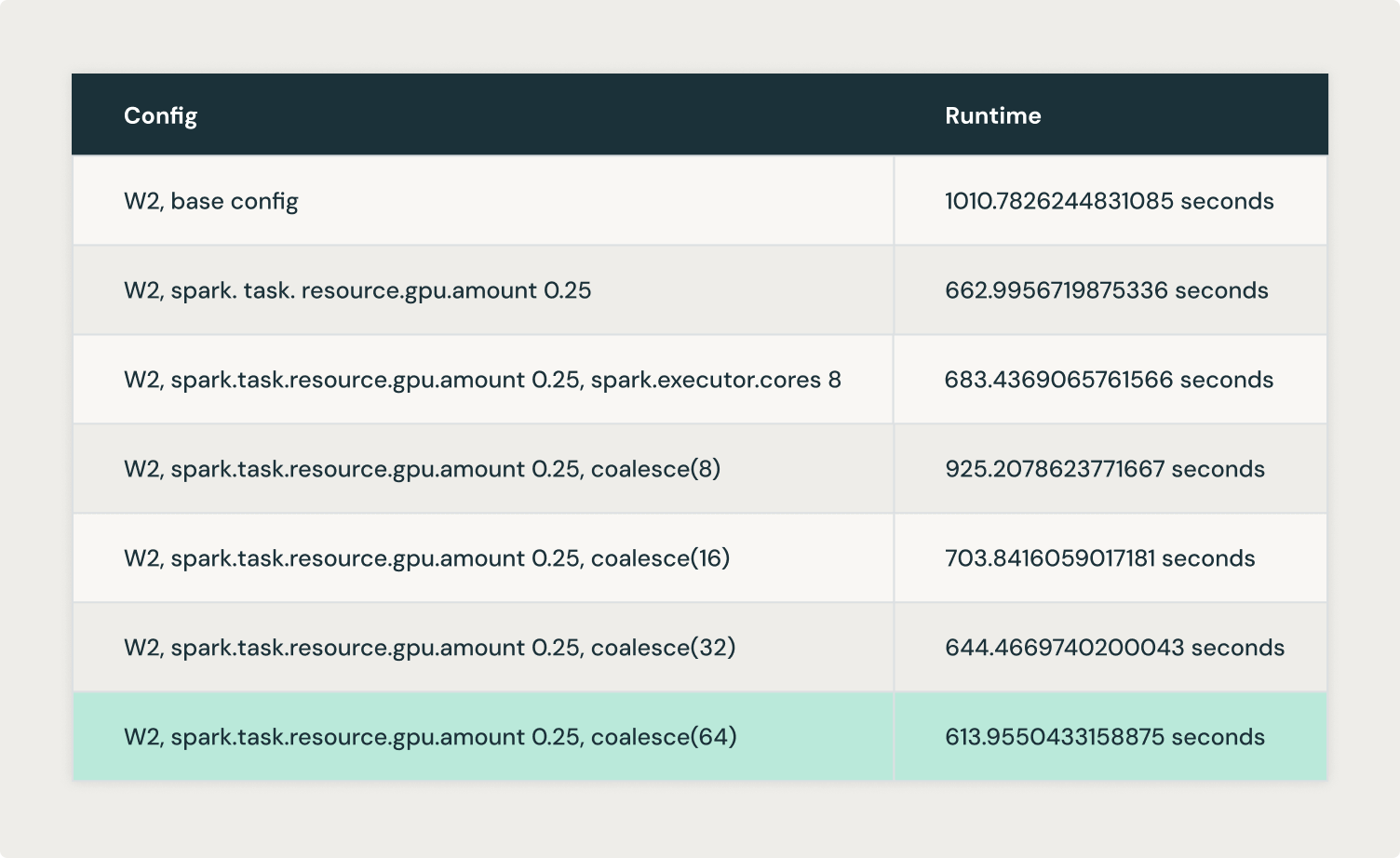
From the above experiments, we understood that there’s a steadiness between how large or small the partitions must be by way of measurement to attain higher GPU utilization. So, we examined the maxPartitionBytes configuration, aiming to create larger partitions from the beginning as an alternative of getting to create them in a while with coalesce() or repartition().
maxPartitionBytes is a parameter that determines the most measurement of every partition in reminiscence when information is learn from a file. By default, this parameter is often set to 128MB, however in our case, we set it to 512MB aiming for larger partitions. This prevents Spark from creating excessively giant partitions that would overwhelm the reminiscence of an executor or GPU. The thought is to have manageable partition sizes that match into obtainable reminiscence with out inflicting efficiency degradation attributable to extreme disk spilling or reminiscence errors.

These experimentations have opened the door to additional optimizations throughout the Logically platform. This contains leveraging Ray to create distributed purposes whereas benefiting from the breadth of the Databricks ecosystem, enhancing information processing and machine studying workflows. Ray can assist maximize the parallelism of the GPU assets even additional, for instance by way of its built-in GPU auto scaling capabilities and GPU utilization monitoring. This represents a chance to extend worth from GPU acceleration, which is vital to Logically’s continued mission of defending establishments from the unfold of dangerous narratives.
For extra data: